
I was working on a project to pitch and due to some things that have happened recently I decided to switch my focus. I don’t think it’s a failure, it’s something that we will have to come back to in the IoT world.
The project itself was about crowd sourcing data (thanks to Sakina’s brilliant insight) and filtering incoming data for the end user to a more manageable chunk. The main reason I wanted to work on it was that I wanted to lower the backend traffic to the web of personal data. With all these IoT devices sending stuff to the cloud, I thought perhaps bandwidth will become an issue. I was also worried about the front end and overloading the end user with information that they might not understand at that point in time and find out only later, “Aw, if I had only known…” Amy Lee had pitched that portion of the idea.
I ended up doing some research along with Amy and we found that there was a team called Syncmetrics that ended up disbanding. We talked to Cas who was leading the team, and there were several points in regards to why they abandoned the project. His project was about synchronizing data points across various fitness devices. ie A scale he bought, and a different food logging system he was using and a fitbit or something to that effect. He saw it as a need for himself and ended up growing the project to 20k people with only 4 people working part time on it.
- scalability was an issue. With all sorts of devices of fitness devices that various companies are putting it, it was hard to scale 4 people part time on it. They were adding APIs almost every week. To give you an idea, FatSecret, CalorieCounter, My NetDiary, MyFitnessPal, LoseIt, … and much more are all Food Calorie Counter websites/mobile Apps that people use. (This is one of the major concerns I have for Project Link) Not all APIs have notifications.
- Data is hoarded. Data is pretty important and some of the things that allow people to make great insights is by looking at trends in data. Even though they dropped the project, they are still working with Universities and such with the data they have.
- They had to be careful around Healthcare and make sure that they weren’t giving recommendations; that they were only showing data analysis. They did this by showing graph comparisons of what people wanted to achieve as a goal such as weight loss/gain versus how much people exercised and how much calories were taken in.
- Error Handling : whether it’s an API error on the other side that needed to get fixed versus user input of people mistaking pounds for kgs or vice versa and then later on realizing that they were inputting it in wrong. This caused data to be off sometimes.
If you want to read my notes, you can find them here : https://public.etherpad-mozilla.org/p/syncmetric_questions Following this, I wanted to create a prototype for a presentation that we were going to pitch.
Part of this prototype was to pull data from the fitbit. After tinkering, doing research and such, I was able to use https://github.com/orcasgit/python-fitbit and created my own branch to pull data. You can take a look at the sloppy code here : https://github.com/nhirata/python-fitbit/commits/heartrate [I admit to being a Python noob/intermediate; I was concentrating on just making something that worked. Not being pretty or thinking about the architecture since it was a prototype. As an afterthought, I probably should have thought of things a bit better].
I changed the authentication measure so that you can log in with just having your Client ID and Client Secret in a config file, and it would handle the session token in a different json file. You would get the Client ID and Secret from the dev.fitbit.com and creating an app there.
Specifically if you cloned my repo, you would have to do those things and then :
git clone https://github.com/nhirata/python-fitbit.git -b heartrate
cd python-fitbit
sudo pip install -r requirements/base.txt
sudo pip install cherrypy
Create config.ini
[Login Parameters]
CLIENT_ID:<client id>
CLIENT_SECRET:<client secret>
run : python gather_keys_oauth2.py
authenticate on the web browser to fitbit
run : python heartrate.py
I couldn’t figure out a way not to use a web browser, and it also mentions in the web api that browserless authentication is not allowed. So in order to the initial connection going you have to run the gather_keys_oauth2.py first, use a web browser to authenticate. There’s methods inside the python-fitbit for refreshing the authentication so you don’t need to worry about that. From running this you can get information on your current heartrate for the whole day in json format. I also pulled out data for the alarms in a json format that was set on the fitbit as well.
The data looks like this :

What was I going to do with this data?
- Store it in a database and get some crowd sourcing data going as a prototype
- Interact with other objects.
I haven’t started on the store as database portion yet, I was going to do that more so after playing around more with the API later this week. Having said that, I’m halting that notion as I stated due to some recent events.
The second part was what I was currently tinkering with.
On the raspberry pi, I got cron gui installed thanks to some info on the Pi site.
sudo apt-get install gnome-schedule
You can then launch the program Scheduled Tasks from the main menu -> System Tools.
I then could potentially run the script for polling data from the fitbit and have it do stuff based on certain activity.
The second part was to setup all sorts of stuff, here is my setup:
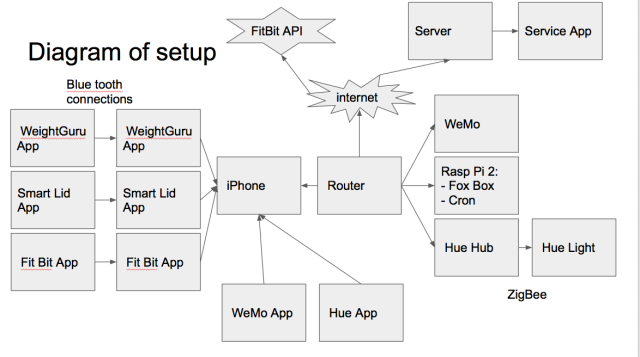
Weight Guru and Smart Lid do already interact with the FitBit. My concern is whether or not they go to FitBit and their own cloud. I haven’t monitored the traffic there.
I’m not also sure whether WeMo or the Hue send packets of data to their respective clouds. Those are still some areas to look into in terms of privacy and data collection that companies are doing behind the scenes. I had set up this subnetwork in side my home and connected the Scale from WeightGuru, the SmartLid from Thermos and Fitbit together.
I also got Hue connected to FoxBox. I’m using Fabrice’s builds :
installing fabrice’s build :
1. on rpi 2 : download a build from https://people.mozilla.org/~fdesre/foxbox/
2. extract it
3. run ./foxbox
While trying to get things working, I ended up talking to NoJun and we ended up finding that you can change the color of the light using foxbox and some of the troubleshooting tips I have are documented in the Tips and tricks I created for the Connected Devices :
https://wiki.mozilla.org/Connected_Devices/QA/Tips_and_Tricks
So authentication and all that stuff is a pain, I took the time to make some Hue_Scripts to interact with the Raspberry Pi 2, I have setup: https://github.com/nhirata/hue_scripts [again, was trying to get stuff up and running. I can refactor a lot… ]
I could have 64 bit encrypted in the script, but this time I didn’t feel like having plain text in a config.ini. The code inside has it commented out, if you want to store your username and password as plain text in the config file.
You would need to run the login.py and I don’t have a mechanism to refresh the token as of yet so it requires you to run login.py when the token expires beofre you run any other script.
I think the README explains most of the scripts. Here are some examples:
So if you fit the pieces together, you could potentially use the cronjob to poll from the fitbit, gather health data that is crowdsource, and also interact with devices real time (ie pulsing light to your heartrate or have the light turned on when you wake or changed color based on your heartrate. Later on I was going to mess with having hot water using the wemo when I wake up. That way I can have coffee (I french press my coffee) and oatmeal in the morning. I haven’t gotten to that point yet. This was a prototype, and the filtering of the data might still be useful both in the backend and the front end. I think though, it might be a little too early for it’s time? I’m not sure if people see what I see yet.
I’m shifting gears and I’m going to be concentrating my time on Vaani and on my spare time WebVR. In case anyone wants to tinker with the stuff I was doing, I just wanted to put it out there.


You must be logged in to post a comment.